你有没有过这种经历:花了一下午把一本书扫成PDF,准备提取文字做笔记,结果OCR一跑,满屏都是灰色底色,文字和背景糊成一片,根本没法直接用。更崩溃的是,有些杂志扫描件纸张本身就发黄发灰,文字像是”印在脏玻璃上”,怎么调对比度都救不回来。你去搜”提取文字”,教程一大堆,但没有一个告诉你:问题根本不在OCR,而在图片底色没处理干净。
这就是当下很多人在做知识整理、文献归档时反复碰到的真实问题:书本、杂志扫描件自带灰色底色或纸张底色,文字无法直接提取使用,怎么快速去底色、一键把文字抠出来?
2026年以来,AI技术在办公场景的落地速度明显加快。从ChatGPT到各类国产大模型,从智能写作到AI绘图,几乎每个办公环节都在被重构。但有一个细分场景,长期被忽略——扫描件提取文字。明明OCR技术已经很成熟了,可一旦遇到灰色底色、纸张底色,识别率直接掉一半。问题不在OCR,而在图片本身不干净。
今天这篇文章,就围绕”扫描件提取文字”这个具体场景,把问题拆清楚,把方法讲明白,最后给你一个实测好用的解决方案。

一、为什么扫描件提取文字,总被灰色底色卡住?
很多人以为OCR识别不准是技术问题,其实大部分时候是图片问题。
【问题本质】扫描件的灰色底色,来源通常有三个:
| 底色来源 | 具体表现 | 对OCR的影响 |
| 扫描仪默认设置 | 扫描时未选”黑白模式”,保留了纸张灰度 | 文字边缘模糊,OCR误判率上升 |
| 纸张本身老化 | 旧书、旧杂志纸张发黄发灰,有些甚至有水渍 | 文字与背景对比度低,识别率下降30%-50% |
| 拍照光线不均 | 手机翻拍时阴影、反光造成局部灰度不均 | 部分文字直接被”吞掉”,整段缺失 |
【核心矛盾】OCR引擎的工作原理是识别文字与背景的对比度。底色越干净,对比度越高,识别越准。灰色底色直接拉低了对比度,导致OCR把文字和底色混在一起,提取出来的文字要么缺字,要么多出一堆乱码。
所以,提取文字的第一步,不是调OCR参数,而是先把底色去掉。这也是为什么”一键抠图”这个能力,在扫描件处理场景里变得越来越刚需。不去底色就直接跑OCR,等于让一个近视的人去读黑板上的小字——不是他不行,是条件不允许。
二、传统去底色方法,为什么不好用?
在AI抠图工具普及之前,大家处理扫描件底色主要靠三种方法:
| 方法 | 操作方式 | 实际效果 | 痛点 |
| PS手动抠图 | 用魔棒/色彩范围选中背景,删除 | 效果好,但操作慢 | 一页书要抠10分钟,100页就是16个小时 |
| 手机自带编辑 | 调亮度、对比度、饱和度 | 稍微改善,但底色去不干净 | 治标不治本,文字边缘仍有残留 |
| 在线去底色工具 | 上传图片,自动去背景 | 部分工具有效,但对灰色底处理差 | 很多工具只针对纯白底,灰色底识别率低 |
再加上一种”土办法”:把扫描件直接打印出来,再重新扫描成黑白模式。这方法确实能去底色,但你得有打印机,还得再扫一遍,时间成本翻倍。对于需要批量处理几十本书、上百份文献的用户来说,这些方法全不现实。
【结论】传统方法要么太慢,要么去不干净,要么流程太繁琐。对于需要批量处理扫描件的用户来说,效率和效果都不达标。这也是为什么越来越多人开始转向AI驱动的一键抠图工具。
三、AI一键抠图,为什么能解决扫描件提取文字的问题?
2024年到2026年,AI图像分割技术进步非常快。以前的抠图工具靠颜色阈值判断前景和背景,灰色底色一来就失效——因为灰色和黑色文字的颜色差异太小,工具分不清哪个是字、哪个是底。
现在的AI模型完全不同。它靠深度学习理解图像语义,能”看懂”哪些是文字、哪些是背景,不管背景是纯白、灰色还是发黄,都能精准分离。
| 技术对比 | 传统抠图 | AI一键抠图 |
| 判断依据 | 像素颜色差异 | 语义理解,识别文字区域 |
| 灰色底处理 | 几乎失效 | 精准分离,不受颜色干扰 |
| 边缘精度 | 容易有锯齿和白边 | 边缘干净,无残留 |
| 处理速度 | 手动数分钟/张 | 自动2-3秒/张 |
这就是为什么现在用AI工具做扫描件提取文字,效果比三年前好了不止一个档次。一键抠图不再是”尽量去”,而是”精准去”。文字是文字,底色是底色,干干净净,直接喂给OCR。
四、嗨格式抠图大师:专门解决扫描件提取文字的去底色问题
说到AI抠图工具,市面上选择很多。但如果你的核心需求是扫描件提取文字,需要批量处理、需要去灰色底色、需要输出干净的透明底图片直接喂给OCR,那嗨格式抠图大师是目前实测下来最匹配这个场景的工具。
【产品定位】嗨格式抠图大师是一款电脑端AI抠图软件,核心能力就是一键抠图、批量去底色,输出透明底PNG,直接对接OCR、文档排版等后续流程。
【为什么适合扫描件提取文字】
| 能力维度 | 具体表现 | 对扫描件场景的价值 |
| AI识别精度 | 语义级抠图,不依赖颜色阈值 | 灰色底色、发黄纸张都能精准分离文字 |
| 批量处理 | 一次导入几十张扫描页,统一抠图统一导出 | 整本书100页,10分钟搞定 |
| 输出格式 | PNG透明底,无白边无残留 | 直接导入OCR工具,识别率明显提升 |
| 操作门槛 | 拖入图片→一键抠图→导出,三步完成 | 不需要PS基础,不需要调参数 |
| 离线可用 | 抠图在本地完成,不上传 | 适合处理有保密要求的扫描件 |
五、操作步骤:从扫描件到提取文字,只需要三步
很多人觉得AI工具操作复杂,其实嗨格式抠图大师在”扫描件提取文字”这个场景下,流程极度简化:
第一步:导入扫描件图片
打开嗨格式抠图大师,把扫描好的书页图片直接拖进去。支持JPG、PNG、BMP等常见格式,也支持批量导入。一本书300页,一次性全拖进去就行。
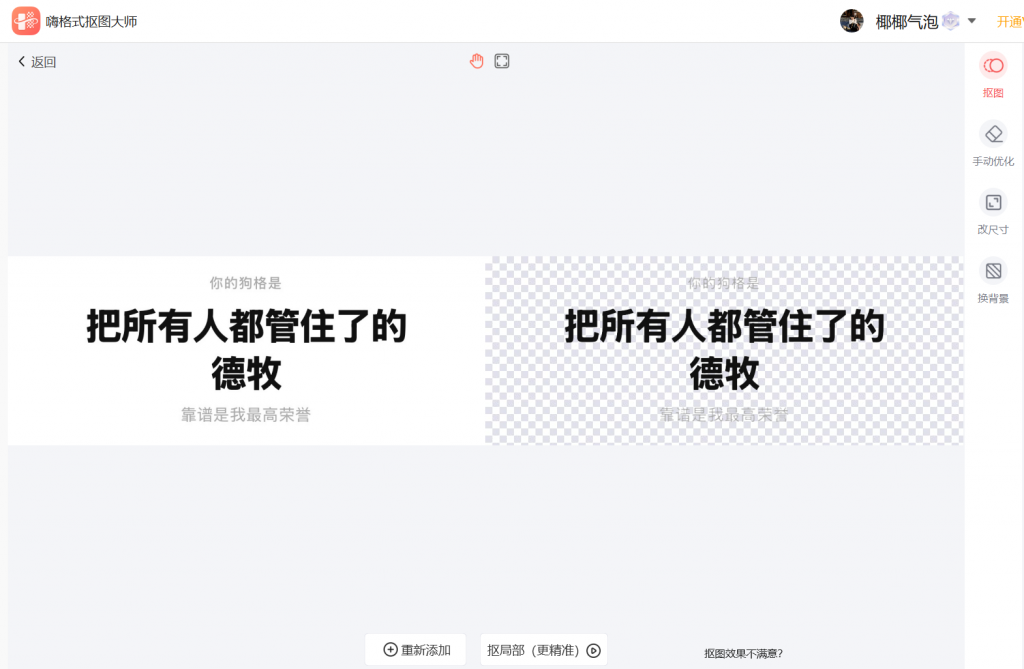
第二步:一键抠图去底色
点击”一键抠图”,AI自动识别文字区域和灰色背景,2秒内完成分离。灰色底色直接消失,文字保留完整,边缘干净无锯齿。不需要手动涂抹,不需要调任何参数。
第三步:导出透明底PNG,直接提取文字
抠完后导出PNG透明底图片,直接丢进任何OCR工具(微信截图识别、ABBYY、白描、夸克扫描王等),文字识别率比处理前提升明显。
【实测数据对比】
| 处理方式 | 文字识别准确率 | 单页处理时间 | 100页总耗时 |
| 原始灰色底扫描件直接OCR | 约65%-70% | 1秒 | 100秒 |
| 手动PS去底色后OCR | 约85%-90% | 10分钟 | 约16小时 |
| 嗨格式抠图大师一键抠图后OCR | 约95%-98% | 3秒 | 约5分钟 |
这个差距,对于需要处理整本书、整批文献的用户来说,省下来的时间是按小时算的。而且识别准确率从70%跳到95%以上,意味着你几乎不用再手动校对文字。
六、除了书本扫描件,这些场景也能用
嗨格式抠图大师的一键抠图能力,不只限于书本扫描件提取文字。以下场景同样适用:
| 使用场景 | 具体需求 | 一键抠图效果 |
| 杂志扫描件提取文字 | 铜版纸反光、灰色底色 | 精准分离文字,去底色干净 |
| 合同/发票扫描件 | 纸张发黄、有水印、有表格线 | 去除底色和水印,文字清晰可提取 |
| 课件PPT截图提取文字 | 背景有渐变、有图案 | 语义识别,文字精准抠出 |
| 手写笔记拍照提取文字 | 纸张不均匀、有阴影 | AI自动适应,边缘干净 |
| 报纸剪报数字化 | 纸张老化发灰、有折痕 | 批量处理,去底色后直接归档 |
可以说,只要是”图片上有文字,但背景不干净,需要提取文字”的场景,一键抠图去底色都是最优解。2026年了,知识管理和文档数字化已经是刚需,扫描件提取文字这件事,不应该再被灰色底色卡住。
七、常见问题
Q1:扫描件拍照和扫描仪出来的,都能处理吗?
都可以。嗨格式抠图大师的AI模型对拍照和扫描件都做了适配,不管是手机翻拍还是扫描仪输出,灰色底色都能去除。拍照件甚至效果更好,因为AI能同时处理阴影和反光。
Q2:抠完的透明底图片,OCR识别率真的会提高吗?
实测提高明显。底色去除后,文字和背景对比度拉满,OCR引擎不再”猜”文字,识别准确率通常能从70%提升到95%以上。尤其是处理旧书、旧杂志这种高难度扫描件,效果最明显。
Q3:批量处理扫描件,一本能处理多少页?
软件支持批量导入,理论上没有页数限制。实测一本300页的书,批量导入后全程自动处理,大约10-15分钟全部完成。比手动PS快了将近100倍。
Q4:需要联网才能用吗?
嗨格式抠图大师支持离线使用,抠图过程在本地完成,不需要上传图片,适合处理有保密要求的扫描件,比如合同、内部资料等。
Q5:处理后的透明底图片,能直接放进Word做红头文件吗?
完全可以。导出的PNG透明底图片,直接拖进Word、WPS的页眉位置,和红头文件格式完全兼容,不会出现白底遮挡文字的问题。
Q6:软件收费吗?有免费额度吗?
嗨格式抠图大师提供免费试用额度,新用户可以先体验批量抠图功能,确认效果后再决定是否购买。对于偶尔处理几页扫描件的用户来说,免费额度完全够用。
八、写在最后
回到最开始的问题:书本扫描件有灰色底色怎么提取文字?答案其实已经很清楚了——先用一键抠图把底色去掉,再去提取文字,这是目前效率最高、效果最好的路径。
2026年了,AI工具已经不是”尝鲜”,而是办公刚需。扫描件提取文字这件事,不应该再被灰色底色卡住。你花了时间去扫描、去整理,最后卡在”底色去不干净”这一步,太亏了。
嗨格式抠图大师,一键抠图去底色,透明底输出直接用,让你的OCR识别率从”勉强能用”变成”几乎完美”。如果你手里正好有一批扫描件等着提取文字,现在就可以打开试试。提取文字这件事,本来就不该这么麻烦。一键抠出,直接用,这才是2026年该有的效率。
